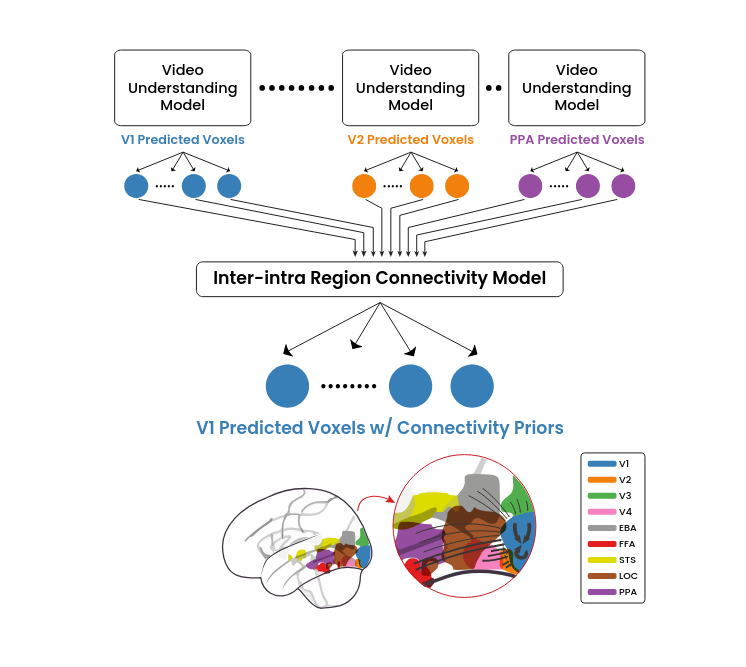
First large-scale study on how the brain processes video stimuli while considering full connectivity. It compares learned representations within deep video understanding models to fMRI recordings of the visual cortex regions.
First large-scale study on how the brain processes video stimuli while considering full connectivity. It compares learned representations within deep video understanding models to fMRI recordings of the visual cortex regions.
Extensive literature has drawn comparisons between recordings of biological neurons in the brain and deep neural networks. This comparative analysis aims to advance and interpret deep neural networks and enhance our understanding of biological neural systems. However, previous works did not consider the time aspect and how the encoding of video and dynamics in deep networks relate to the biological neural systems within a large-scale comparison.
Towards this end, we propose the first large-scale study focused on comparing video understanding models with respect to the visual cortex recordings using video stimuli. The study encompasses more than two million regression fits, examining image vs. video understanding, convolutional vs. transformer-based and fully vs. self-supervised models.
Our study resulted in both, insights to help better understand deep video understanding models and a novel neural encoding scheme to better encode biological neural systems. We provide key insights on how video understanding models predict visual cortex responses; showing video understanding better than image understanding models, convolutional models are better in the early-mid visual cortical regions than transformer based ones except for multiscale transformers and that two-stream models are better than single stream.
Furthermore, we propose a novel neural encoding scheme that is built on top of the best performing video understanding models, while incorporating inter-intra region connectivity across the visual cortex. Our neural encoding leverages the encoded dynamics from video stimuli, through utilizing two-stream networks and multiscale transformers, while taking connectivity priors into consideration. Our results show that merging both intra and inter-region connectivity priors increases the encoding performance over each one of them standalone or no connectivity priors. It also shows the necessity for encoding dynamics to fully benefit from such connectivity priors.
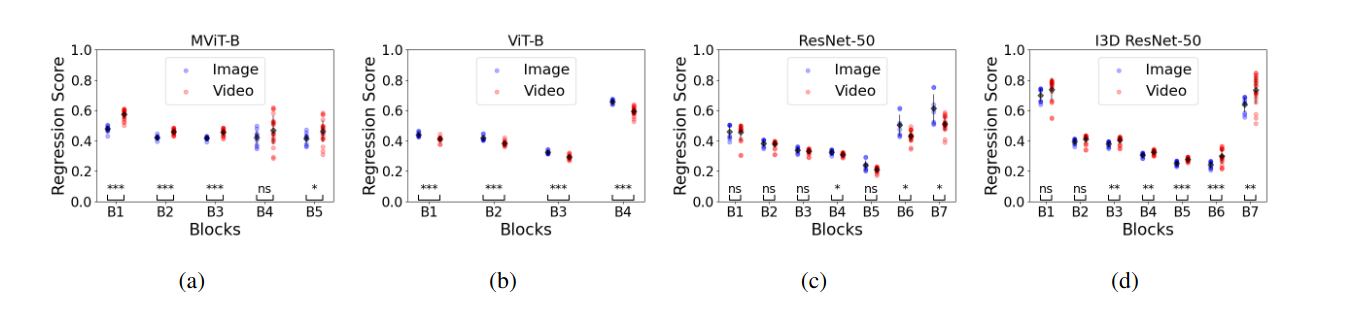
Artificial neural network target experiments showing regression scores as Pearson’s correlation coefficient of image (blue) vs. video (red) model families on four target models; (a) MViT-B, (b) ViT-B, (c) ResNet-50, (d) I3D ResNet-50. We show the regression on the target network output features from their respective blocks, B1-7. Statistical significance is shown at the bottom as ‘ns’ not significant, ‘∗, ∗∗, ∗ ∗ ∗’ significant with p-values < 0.05, 0.01, 0.001, respectively. It shows higher scores for the model family corresponding to the target network, especially in MViT and ViT.
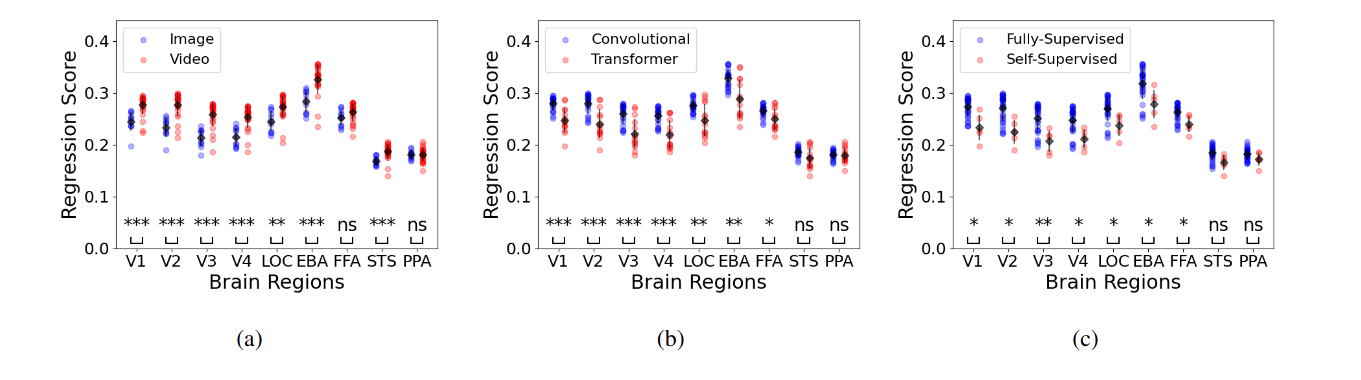
Biological target experiments showing regression scores as Pearson’s correlation coefficient of model families on brain fMRI data. Comparison between: (a) image vs. video understanding models, (b) convolutional vs. transformer-based models and (c) fully supervised vs. self-supervised models. Statistical significance is shown at the bottom as ‘ns’ not significant, ‘∗, ∗∗, ∗ ∗ ∗’ significant with p-values < 0.05, 0.01, 0.001, respectively. It shows video understanding models outperform single image ones, fully supervised outperform self-supervised ones and convolutional models surpass transformer-based ones in early-mid regions.
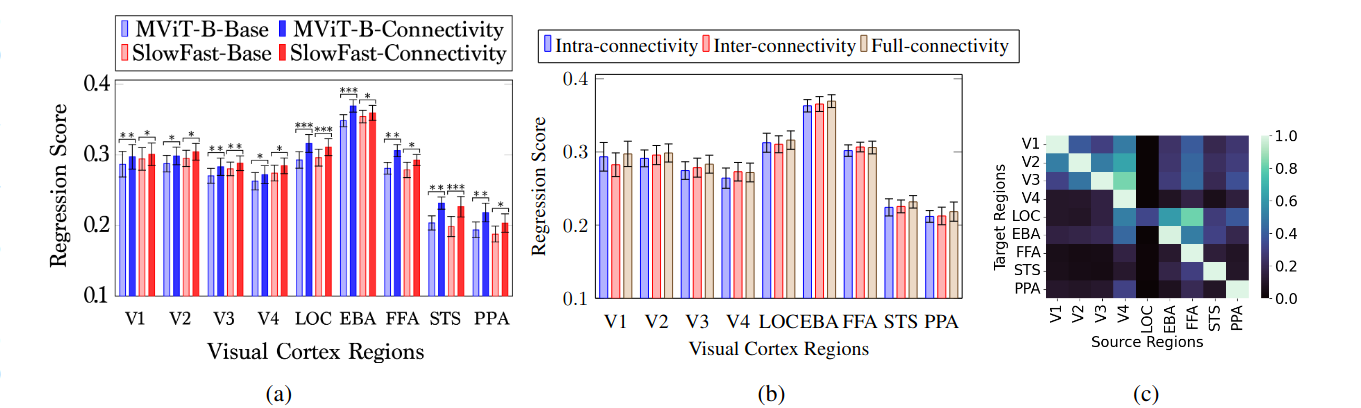
(a) Comparison of base model accuracies of MViT-B-16×4 and SlowFast and their accuracies after incorporating the intra-region and inter-region voxel connectivity showing the Pearson’s correlation coefficient as the regression scores. It shows the superiority of the connectivity-based models.
(b) Comparison of performance enhancement by incorporating the intra-region and inter-region voxel connectivity together or each of them separately showing the Pearson’s correlation coefficient as the regression scores. It confirms the need for combining both intra- and inter-region connectivity.
(c) Average weights per region contributing to the accuracy enhancement of each target visual region, showing the directional learned connectivity in our model.
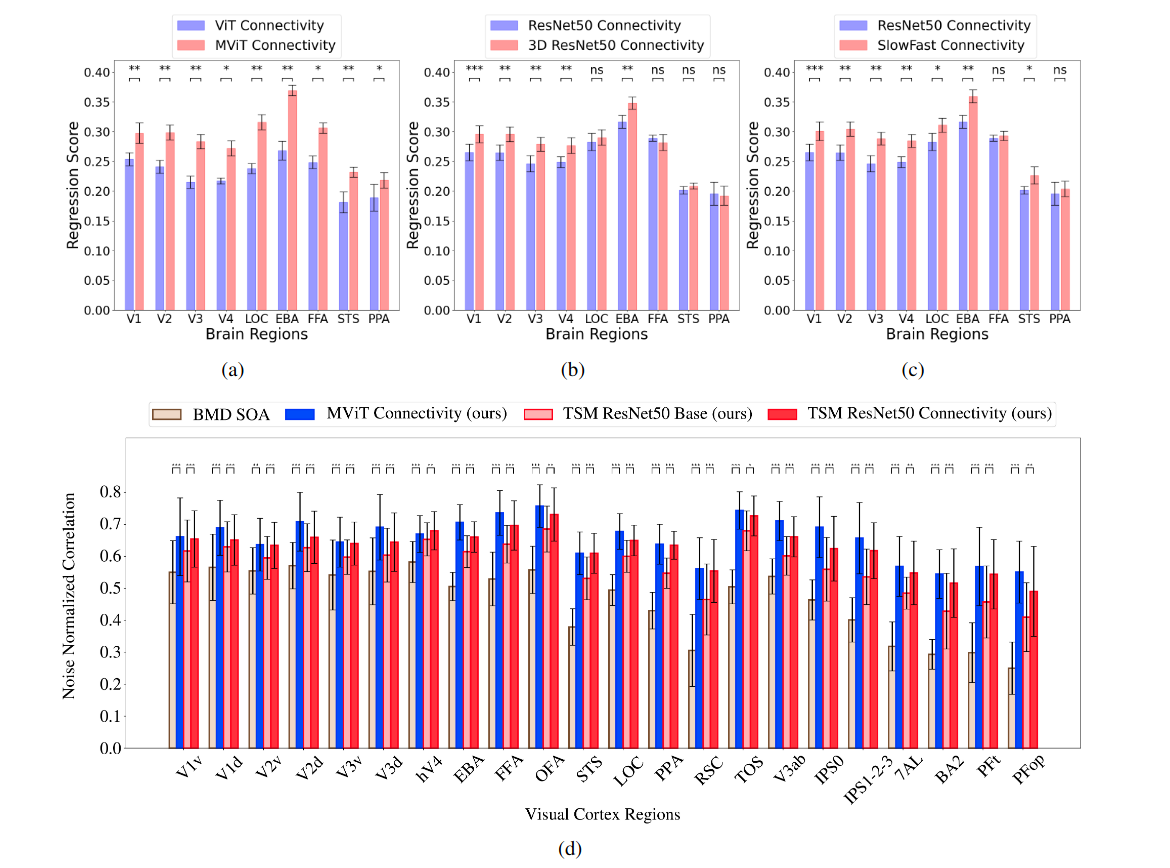
(a-c) Comparison between image and video models after incorporating connectivity priors. (a) ViT vs MViT, (b) ResNet50 vs 3D ResNet50, and (c) ResNet50 vs SlowFast.
(d) Comparison between BMD SOA (using TSM ResNet50 third block features) and our models (MViT connectivity, TSM ResNet50 Base, and TSM ResNet50 Connectivity). Statistical significance is shown as ‘ns’ not significant, ‘∗, ∗∗, ∗ ∗ ∗’ significant with p-values < 0.05, 0.01, 0.001, respectively.
@article{gamal2024dynamics,
title={Dynamics Based Neural Encoding with Inter-Intra Region Connectivity},
author={Gamal, Mai and Rashad, Mohamed and Ehab, Eman and Eldawlatly, Seif and Siam, Mennatullah},
journal={arXiv preprint arXiv:2402.12519},
year={2024}
}